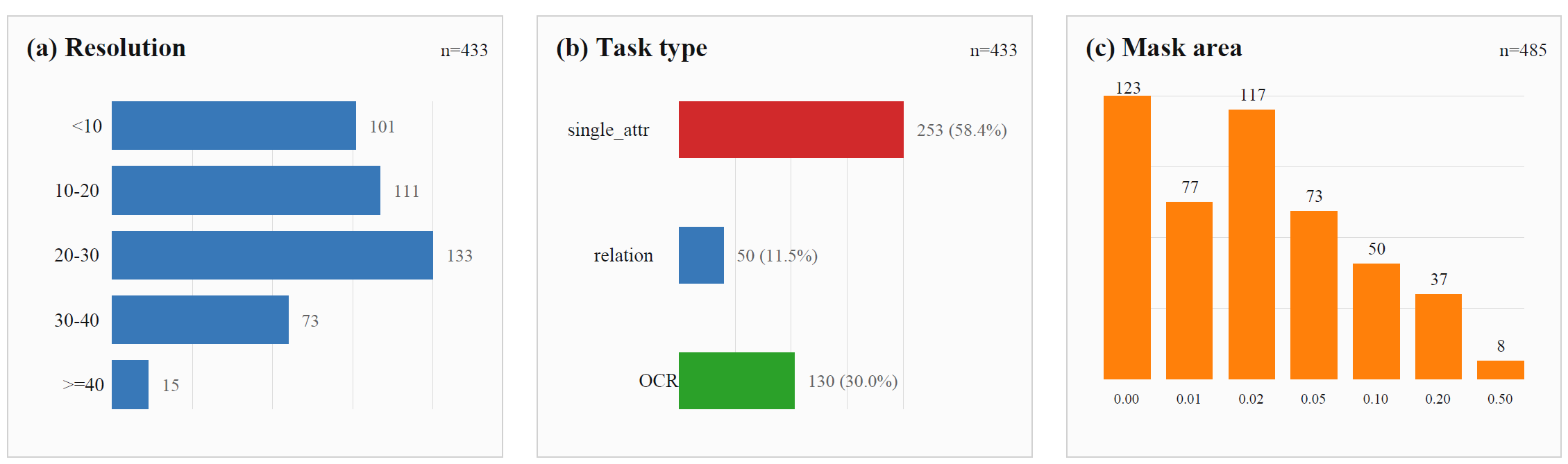
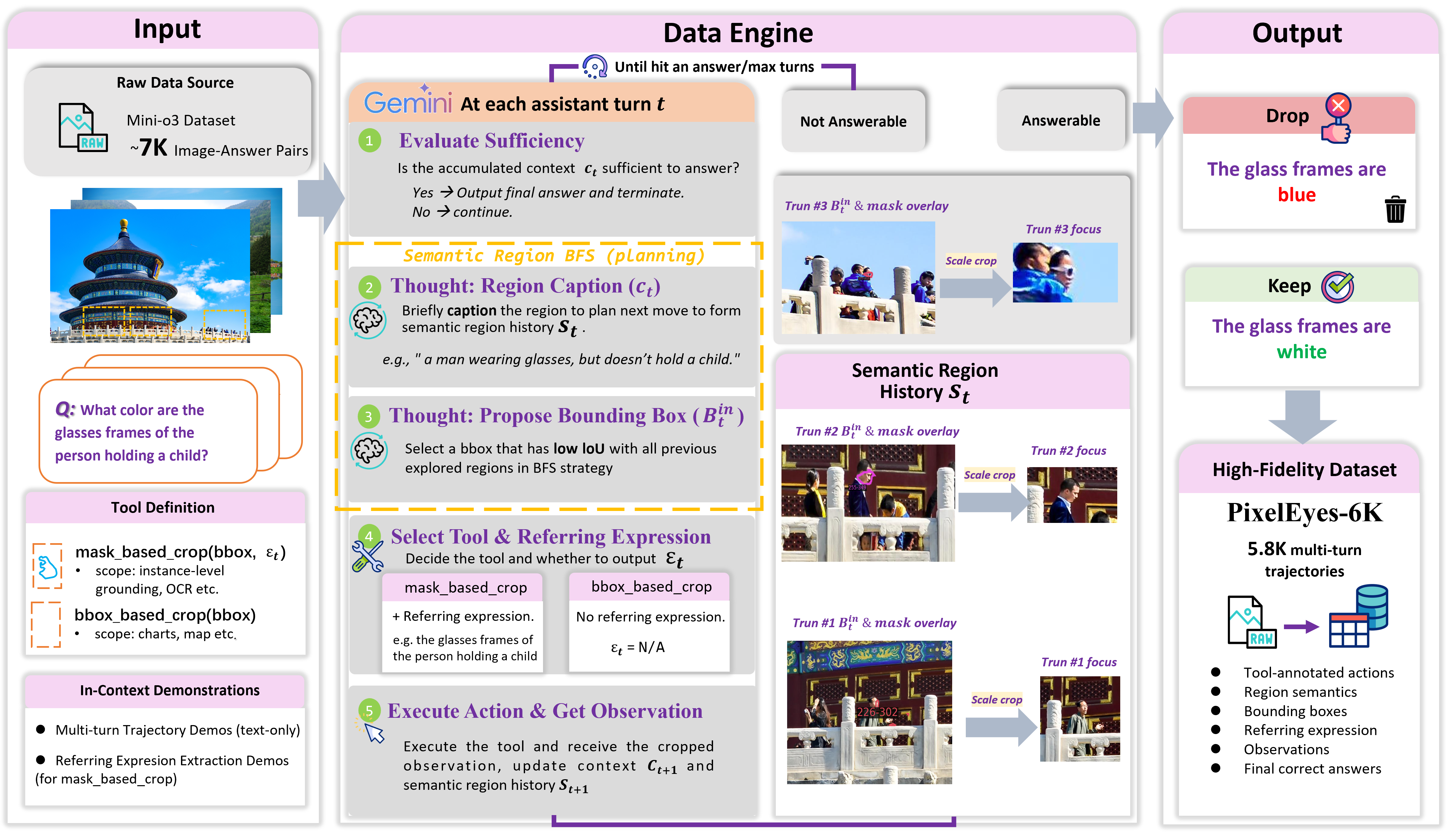
Search Trajectory Demo
PixelEyes repeatedly proposes a search region, runs SAMTok grounding, computes a crop from the mask, and continues until enough evidence supports an answer.

What is the line of text below "30.480 KGS"?
Round 1 Search

Localized Target

Prediction
67.200 LBS
GT: 67.200 LBS